
Music Identification (Fingerprinting)
Between the years 2009 and 2012 I worked on a project to create a fast and reliable music identification program (fingerprinting) for a potential client… from scratch!
For reasons I still don’t understand, the interest in the project vanished and I ended wasting quite a lot of time of both R&D and actual development and testing.
In case you don’t know, music identification (also known as fingerprinting, depending on the algorithm you use) is a process that uses one or more algorithms to identify music or audio clips using a computer program.
Basically, that’s what you do when you use Shazam or SoundHound on your phone.
The process is quite simple (although implementing it can be quite a challenge):
- Learn: Feed the program with music and/or audio clips
- Process: Use some sort of algorithm to extract audio features from the audio
- Store: Store that information in a database
- Listen and compare: Then, playback some audio and let the program compare it to the extracted features in its database
- Identify: Finally, find a list of the best matches based on the extracted features
As per the client’s request, there were two major requirements for this solution:
- It had to be able to identify music in real time, providing accurate information about the track position (that is, where in the track was the audio being monitored), its quality and whether it was played in its entirety.
- It also had to do it in such a way that it would allow it to identify very small clips of audio (less than 30 seconds in length).
- And, finally, it should be agnostic to the track’s tempo or speed at which it was being played.
When I started working on this project there wasn’t a lot of information and the way this is done was kept as a very well guarded secret with most of its implementations under patents by very large corporations.
This made it very hard and it took me several months (almost a full year) to come up with a working proof of concept which I kept perfecting until the project was discarded.
Amazingly, today (just four years later), there’s tons of information and even an open source project!
Oh well…
So, how does this fingerprinting thing works?
Well, my implementation is based on the “A Highly Robust Audio Fingerprinting System” paper by Jaap Haitsma and Ton Kalker from Phillips Research.
One way in which you could compare two pieces of audio, from a digital media, is by comparing each and every bit of both audio sources. Unfortunately, this wouldn’t work unless you could guarantee that each source is kept perfectly intact and that there is no possibility of one of those bits from ever changing due to volume changes, quality changes, speed changes, etc…
Even if you play the exact same MP3 file using two different audio players, if each player uses a different MP3 decompression algorithm, the resulting bits that make up the audio that will be fed into the sound card will be completely different… although, to our ears, they will sound identical.
What the actual algorithm does is to extract certain audio features (called hashes) that are more prominent than others, in such a way so that the extracted features are less sensible to distortions.
The resulting list of hashes that identify an audio clip is known as a fingerprint.
So, basically, the algorithm analyzes various frequency bands (while it discards others) and compares their energy against contiguous frames to determine their relative “relevance”.
For this to work, we need to “transform” the audio being monitored into the frequency domain.
This is done using a fast Fourier transform algorithm, which luckily, I had already implemented for the DXVUMeterNET control.
Next, a process analyzes a series of bands of frequencies and extracts their energy.
A final process compares those energies with adjacent bands and frames to determine their relative relevance. This is what’s known as “fingerprinting” an audio clip.
Now that we have a set of audio features that model the source audio clip, we simply store that information in a database.
The process of identifying an audio clip is quite similar but instead of analyzing a complete portion of audio we take small samples (3 – 5 seconds), run those samples through the same fingerprinting process and then do a comparison loop through ALL the fingerprints stored in the database.
Here is where things start to get complicated.
An average 5 minutes long audio clip can produce about 3,000 hashes (depending, again, on your algorithm and its settings).
This means that a database with just 20,000 tracks will contain 60 million entries!
So how do we run a comparison loop, every 3 seconds (which is the average length of the audio being monitored) against 60 million rows of hashes?!?!
You could, of course, alter the algorithm parameters so that it produces fewer hashes per audio clip, but that results in a considerable increase in false positives.
The more audio features you extract, the more robust the algorithm will behave.
The solution I implemented is to generate a second set of fingerprints. One that contains only the most relevant hashes out of the extracted relevant hashes.
In this case, this sub-set of hashes averages about 150 hashes per audio clip, reducing the comparison loop from 60 million to about 3 million.
A good database, running on a fast computer (and having the database on an SSD) is quite capable of handling this routine. Actually, it runs so fast that I have been able to run multiple instances (around 10) of the music identification program simultaneously.
This sub-set of fingerprints is then used to generate a list of several possible candidates, thus reducing the number of tracks that will be fully compared against the main set of fingerprints.
There is just one final issue. I mentioned before that performing bit to bit comparisons is a bad idea, even when using fingerprints.
So what I do is that I use something known as the Hamming Distance. This allows us to compare two streams of bits of equal length and provide us with a measure of how similar they are, or more accurately, how much one stream needs to change to become the other.
This is the way hashes are compared in the program.
It works great but it tends to be a bit quite slow… unfortunately, I haven’t found any other solution or workaround.
But, does it actually work?
The short answer is: YES!
The long answer is: there are still a few bugs that need to be worked out.
These are minor bugs that do not prevent the program from serving as a proof of concept that can be further developed and perfected.
Here’s the list of known bugs:
 The Tracks Manager
The Tracks Manager
This is the application used to analyze audio clips and populate the database
- There’s an obscure bug that makes it crash from time to time, specially if you analyze a set of tracks and then, when it finishes, you try to analyze another batch.
Closing it and re-opening it solves the problem… - Its interface is not very user friendly and needs a complete rework so that it is easier to use to manage thousands or even millions of tracks.
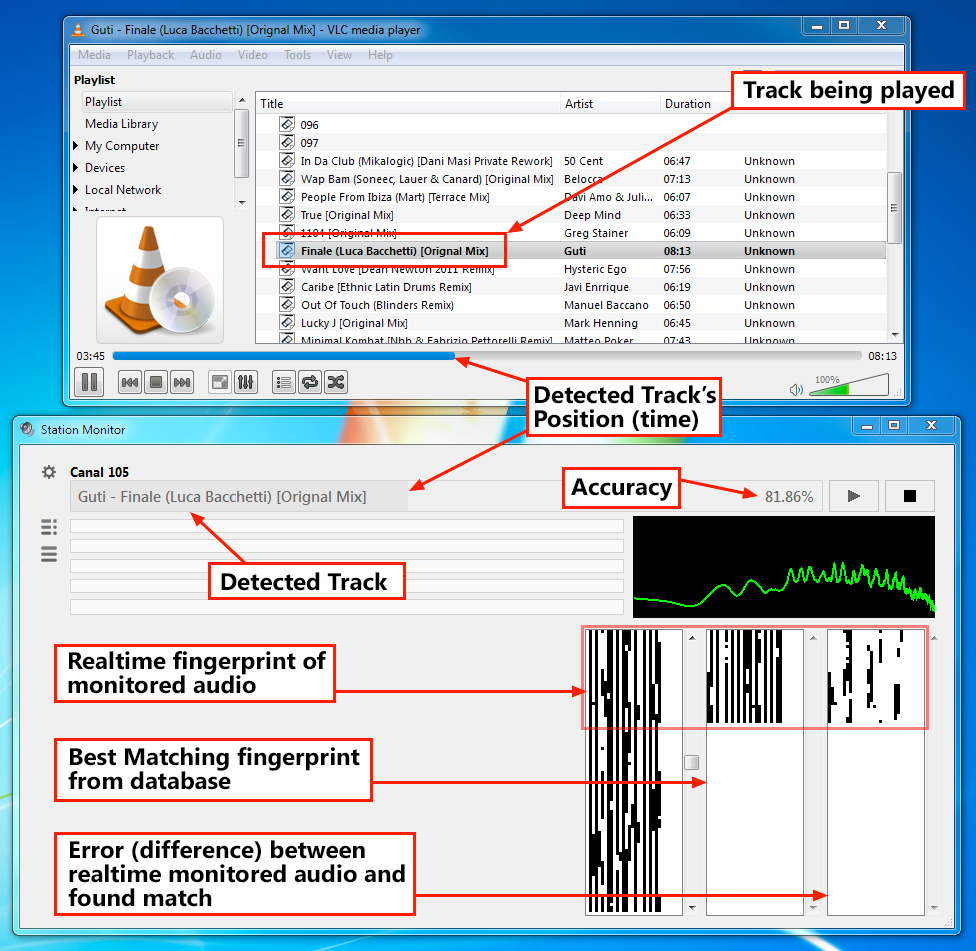 The Monitor
The Monitor
This is the application that monitors audio, performs the comparisons and determines if the audio being monitored resembles something in the database
- When the Monitor identifies a track with sufficient confidence it “locks it” and minimizes further comparisons to preserve CPU cycles.
But, for some reason, from time to time, it has the tendency to “unlock it” and completely discard it. Then the full identification process starts again, locking the track once more. - The algorithm that discards identified tracks (maybe because their duration was too short or their score was too low) needs to be rewritten from scratch as its the slowest process in the program and doesn’t work very well.
- The worst of the bugs (as this one is a show stopper) is that the memory consumed by the Monitor appears to never be released and, after a while, the program simply freezes or crashes with an OutOfMemoryException.
I have implemented a “manual routine” that forces .NET’s garbage collector to do its thing and this seems to alleviate the problem but it makes the program unstable and slow. - The algorithm tends to match similar frames to the ones at the end of the track. Many songs start and end quite similarly (specially dance/house/techno music) or perhaps, contain very similar passages (such as the repeated chorus parts) and for some weird reason, the frames closest to the end of track produce better scores, completely ruining the process that determines the current position of the track being analyzed.
- The interface is far from finished…
The Database
The current implementation uses Microsoft’s SQL Server 2008 R2 Express but, quite probably, I’ll migrate to either MySQL or PostgreSQL.
Alright. So let’s see it in action!
…coming soon:
- Video demonstration
- Compiled binaries
- Some portions of source code
- Enhanced algorithms for speed and accuracy (plus many bug fixes)
- Gender (male/female) recognition, for both known and unknown tracks
- Purchase/licensing options
Recent Comments